
FIRE: The “Weight Reset” That Finally Stops Guessing
A tuning-free way to make neural nets learn again—without wiping their memory like a goldfish in a blender.

There’s a particular kind of tragedy in modern machine learning.
You build a model. It learns. It gets good. It becomes useful. And then—quietly, without drama, without a loud crash—it starts to harden. It still produces outputs. It still looks alive. But inside, the learning machinery is turning into dried cement.
In continual learning, in reinforcement learning, in long-running pretraining runs, this is the real villain. Everyone talks about catastrophic forgetting because it has a great name and an even better headline. But the more existential problem is often the opposite:
Your model stops being able to learn new things at all.
It doesn’t forget.
It fossilizes.
And that’s why the paper FIRE: Frobenius-Isometry Reinitialization for Balancing the Stability–Plasticity Tradeoff exists, along with its code. The authors take a messy, folklore-ish practice—“reset the weights a bit and hope for the best”—and turn it into something crisp, geometric, and, crucially, not based on vibes.
Which is refreshing. Because “vibes” are how you pick a restaurant. Not how you keep a 10-million-step agent from becoming a statue.
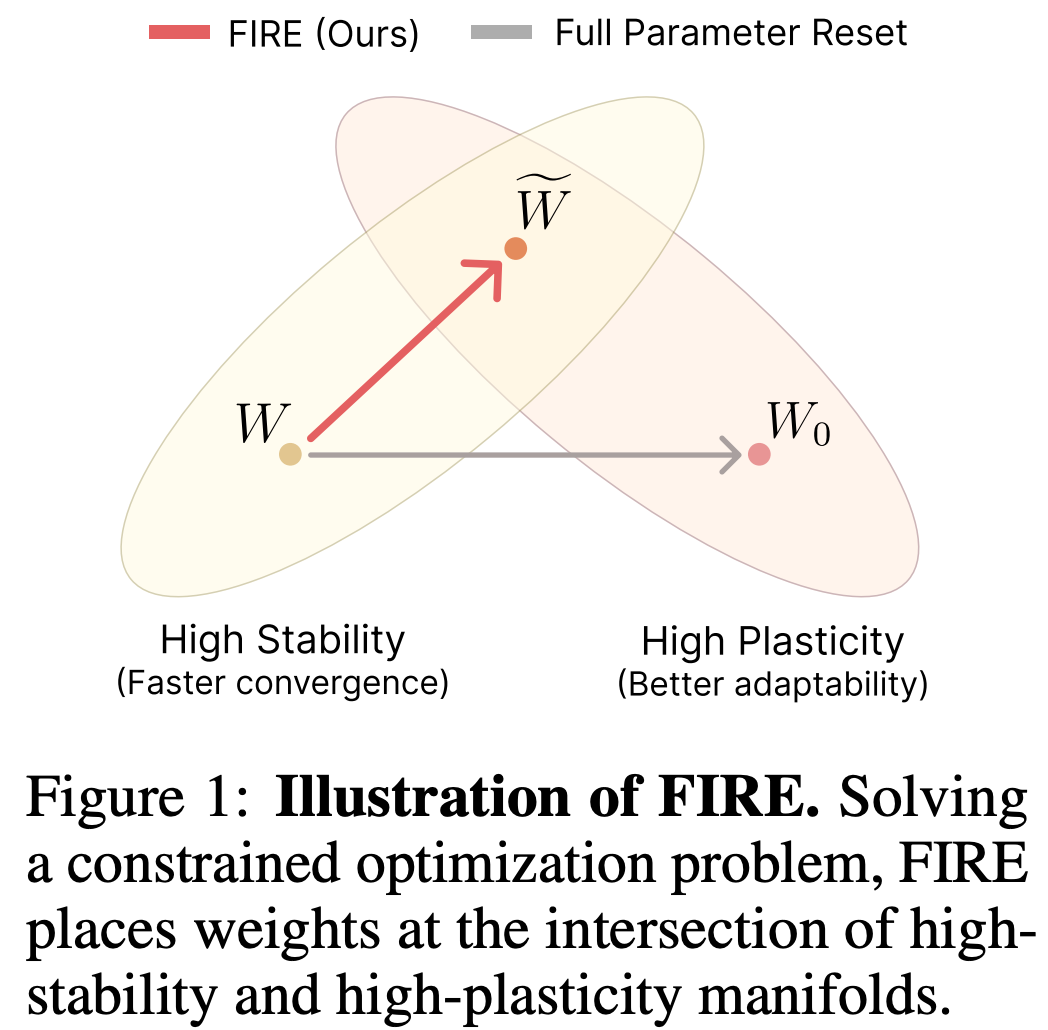
The problem: stability vs plasticity (and why everyone gets it backwards)
Neural nets in non-stationary environments face a brutal tradeoff:
Stability: keep what you’ve learned (don’t ruin representations).
Plasticity: keep the ability to learn (don’t become rigid).
In the real world, you need both. In practice, you usually get one.
Over time, especially in RL and continual training, weight matrices tend to lose their “nice” properties. Effective rank collapses. Gradients stop flowing cleanly. Some neurons basically stop participating. The model becomes a well-trained bureaucrat: excellent at last year’s rules, completely useless the moment the form changes.
Historically, people tried two categories of fixes:
Regularization (keep weights from moving too much during learning)
Reinitialization (occasionally shake the model loose)
Reinitialization tends to work better when the model is stuck—because sometimes you don’t need a gentle reminder, you need a controlled earthquake.
But until now, the standard methods have been… let’s call them “artisanal.”
The classic example is Shrink & Perturb: shrink weights and add noise. Great. How much noise? Nobody knows. You tune it. Then you tune it again. Then you discover it breaks when you change the task. Then you tune it some more, because you apparently hate weekends.
FIRE’s promise is simple:
Stop tuning noise. Start solving the right math problem.
The core idea: don’t add randomness—project to the nearest “learnable” matrix
FIRE reframes “resetting weights” as a principled optimization problem.
It says: we want new weights W_{\text{new}} that satisfy two constraints:
1) Stay close to the old weights (stability)
This is measured by Squared Frobenius Error (SFE):
\| W - W_{\text{new}} \|_F^2
Minimize this and you preserve learned structure. Your internal representations don’t suddenly teleport into nonsense.
2) Restore a learnable geometry (plasticity)
This is measured by Deviation from Isometry (DfI):
\| W^T W - I \|_F^2
Low DfI means the matrix is close to orthogonal / isometric: singular values near 1, better signal propagation, healthier gradients, fewer “dead” directions.
This connects to a well-known theme: dynamical isometry. Networks learn best when their transformations don’t squash or explode information as it flows.
So FIRE sets up the bargain like this:
Keep the weights almost where they are…
but make them behave like a fresh, well-conditioned layer again.
That becomes:
Minimize stability cost (SFE) subject to perfect isometry (DfI = 0).
And that problem has a clean classical solution: the Orthogonal Procrustes / polar decomposition projection:
W_{\text{new}} = W (W^T W)^{-1/2}
Translation: keep the “direction” of what you learned, but fix the scaling and conditioning so the layer is learnable again.
This is the opposite of random noise. It’s a reset with a steering wheel.
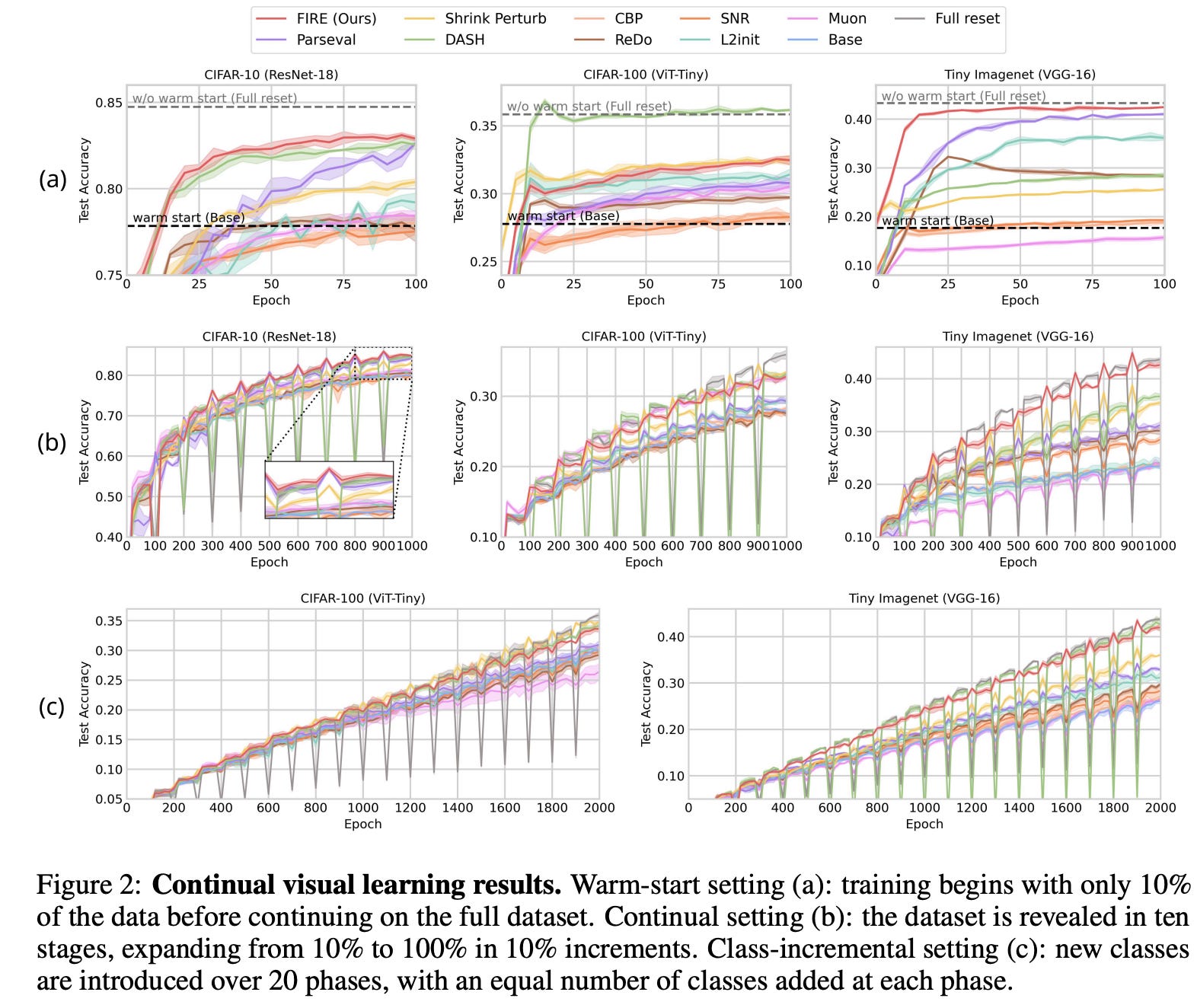
“But that looks expensive.” Yes. And then: Newton–Schulz.
If you do that projection naively, you’ll reach for SVD, matrix inverse square roots, and other things that make GPUs sigh and accountants cry.
FIRE avoids that with the Newton–Schulz iteration, which approximates the orthogonalization using only matrix multiplications:
X_{k+1} = 1.5X_k - 0.5X_k (X_k^T X_k)
It converges fast (quadratically, in the nice regimes), it’s GPU-friendly, and in the paper’s setup ~5 iterations are enough in practice.
Net effect: the “reset step” adds under ~1% training overhead in many cases.
So you get a mathematically grounded reset that’s cheap enough to actually use, not just admire.
Where this matters most: reinforcement learning’s graveyard of dormant neurons
If you’ve done serious RL, you’ve seen it:
The agent learns early.
Then performance plateaus.
Then you tweak exploration.
Then you tweak the reward.
Then you tweak the optimizer.
Then you consider moving into forestry.
Often, what’s really happened is that the model has lost plasticity. The network’s internal dynamics become less responsive. Units go dormant. It’s not “bad hyperparameters” so much as “the model is no longer a good learner.”
FIRE targets exactly that failure mode.
The paper reports that in RL benchmarks (e.g., Atari and HumanoidBench setups), FIRE reduces dormant neurons and restores healthier geometry (low DfI) while keeping weights close (low SFE). That combination is the whole point: plasticity without amnesia.
This is why FIRE feels like a genuine upgrade over Shrink & Perturb:
S&P is a knob you tune.
FIRE is a projection you compute.
And the difference between those two approaches is the difference between medicine and homeopathy.
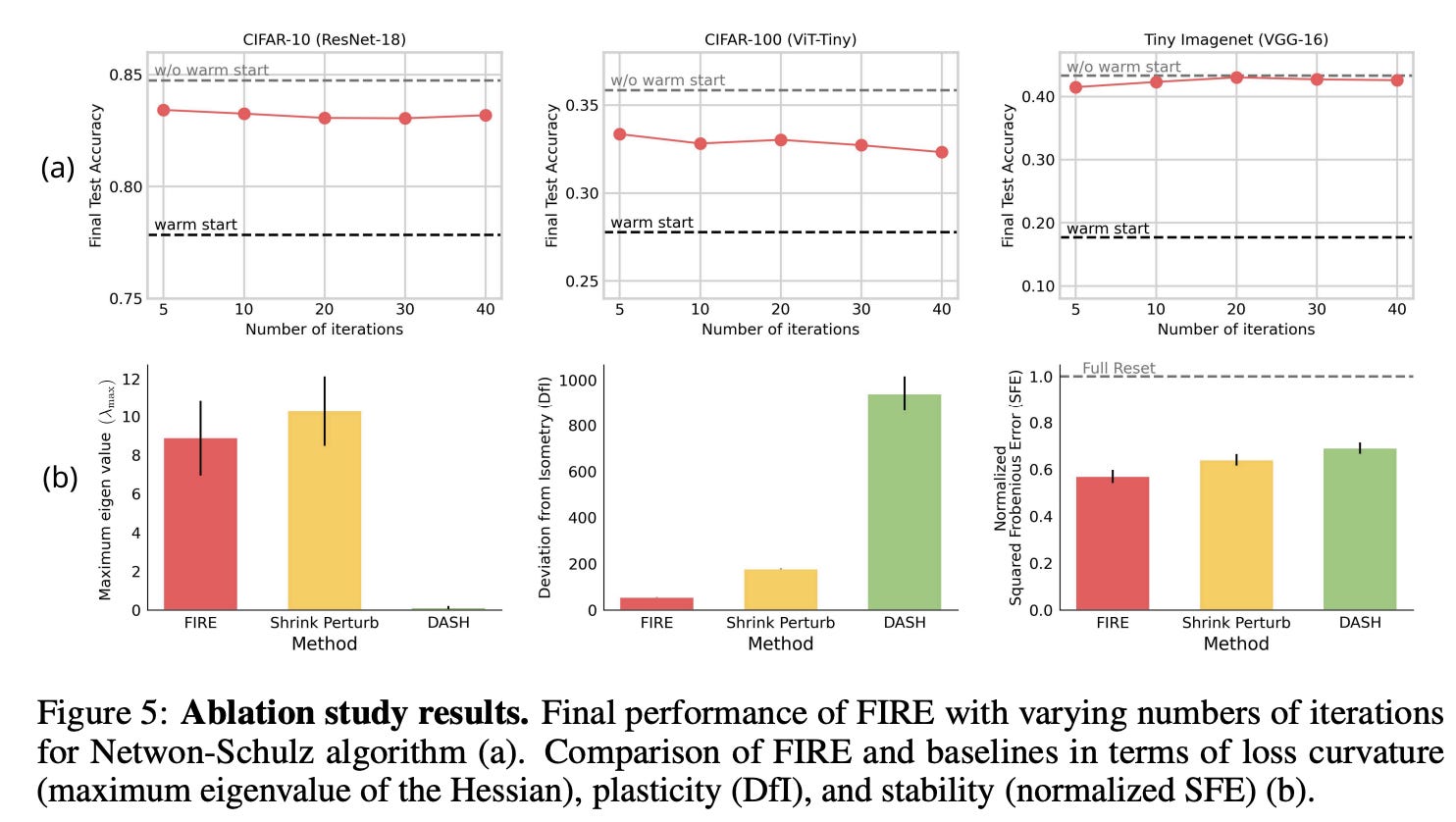
It’s not just RL: vision and language also benefit
The authors test FIRE across:
Vision (CNNs / ViTs)
LLMs (continual pretraining on a ~0.1B model)
RL (where plasticity loss is most punishing)
A particularly important observation: in transformer-ish models, FIRE isn’t applied everywhere blindly. The paper notes better outcomes when orthogonalization is focused on Q and K projections (the parts most tied to attention geometry). Applying it to V or MLP layers can be harmful.
This is a recurring lesson in 2026: the best methods aren’t “one size fits all,” they’re “one size fits the physics of your architecture.”
But FIRE still remains attractive because it’s not a fragile, gradient-heavy intervention. It’s a controlled geometric step.
The practical appeal: it’s “tuning-free” in the way engineers actually mean it
Many papers claim they’ve eliminated hyperparameters. Then you read the appendix and discover fourteen secret schedules, three warmups, and a ritual involving candles.
FIRE is refreshingly close to what it advertises:
The Newton–Schulz coefficients are fixed.
The method is deterministic.
You don’t have to guess a noise magnitude.
You don’t have to A/B five perturbation levels and pretend that’s science.
You still need to decide when to apply FIRE (on a schedule, at task boundaries, when learning stalls), and where to apply it (which layers). But that’s strategic configuration, not tuning a random-number generator.
How FIRE relates to the broader “orthogonal everything” trend
If you’ve been watching optimization methods lately, you may have noticed a theme: orthogonalization keeps popping up like a useful weed.
FIRE’s Newton–Schulz usage echoes methods like Muon, which orthogonalize updates/gradients. The difference is philosophical:
Muon-style approaches change how you step.
FIRE changes the state you’re stepping from.
One is driving technique. The other is straightening the wheels before you drive again.
What FIRE does not magically solve
Let’s be honest, because the universe insists.
FIRE is not a complete continual learning solution. It’s a plasticity restoration tool.
It doesn’t eliminate forgetting by itself.
If you never replay old data (or have some equivalent mechanism), drift can still happen.
In the paper, a replay buffer is part of the story in the continual/RL settings.
Also, the LLM results are on a smaller model (~0.1B). That’s meaningful as a proof of mechanism, but it’s not the same as proving behavior at 70B+ where optimization dynamics can get… weird.
Still, as an intervention that costs almost nothing and fixes a real failure mode, it’s hard to ignore.
The bigger point: we’re moving from “shake the box” to “fix the geometry”
For years, the “reset weights” family of tricks has felt like folk wisdom:
“Add noise.”
“Reset some layers.”
“Shrink the weights.”
“Hope.”
FIRE is a shift away from that. It treats the network’s matrices as objects with geometry you can repair, not mystical artifacts you must appease.
And that’s why this paper matters beyond its benchmarks.
Because continual learning, long-horizon RL, and ongoing pretraining are not edge cases anymore. They are the entire direction of travel.
The future belongs to systems that don’t just learn once.
They learn, adapt, recover, and keep going.
FIRE is not the whole machine. But it’s a very good wrench for a very common breakdown.
A clean way to think about when you should try FIRE
If you’re building anything that learns over time, FIRE is worth testing when:
learning stalls after early progress,
your agent seems “stuck” despite data diversity,
effective rank collapses,
you see dormant neurons increasing,
continual training starts to degrade even with replay.
And if you’re currently using Shrink & Perturb with a lovingly curated noise schedule?
Try replacing the guesswork with geometry.
At minimum, you’ll save time.
At best, you’ll resurrect a model that had quietly given up.

Final thought
There’s a romantic idea that a trained neural network is “mature.” Settled. Confident.
In practice, a mature neural network is often just… tired.
FIRE is a reminder that sometimes the best way to make a model smarter isn’t more data, more tokens, more compute, or more motivational speeches.
Sometimes it’s just:
Make the matrices behave again.