
Talkie: The Language Model Trapped in 1930
A 13B model trained only on pre-1931 text lets us ask a beautifully strange question: can AI predict the future if we lock it in the past?

There is a new language model called Talkie, and the basic premise is so good it sounds like something a bored physicist would invent after too much sherry:
What if you trained an LLM, but stopped its world in 1930?
No internet. No World War II as common knowledge. No computers in the modern sense. No moon landing. No Cold War. No ChatGPT. No crypto. No influencer marketing. No man on LinkedIn explaining leadership through the metaphor of sourdough.
Just the world as it existed before 1931, compressed into a 13-billion-parameter model and made available to chat with.
The result is Talkie, a “vintage language model” trained on 260 billion tokens of historical pre-1931 English text. According to the team, it is the largest vintage language model they are aware of. The authors are Nick Levine, David Duvenaud, and Alec Radford, which is worth noting because Radford trained the original GPT. In other words, this is not three men in a shed teaching a chatbot to say “good heavens” for fun, although that would also be admirable. It is a serious research experiment wearing a tweed jacket.
You can try the chat version here: Talkie chat. There may be a queue. If you are impatient, or simply the sort of person who thinks “I would rather download the brain of 1930,” the weights are on Hugging Face.
The main project write-up is here: Introducing Talkie.

The cutoff date is not just aesthetic. In the United States, works published before 1931 are in the public domain, which makes the data story much cleaner than the usual modern AI buffet, where every dataset is a legal thriller pretending to be a CSV file. Talkie’s corpus includes books, newspapers, periodicals, scientific journals, patents, and case law from before 1931.
And that is where this stops being a parlor trick.
Because the point is not merely to build a chatbot that sounds as if it might object to jazz.
The point is to test whether language models can generalize beyond their training data in a much more rigorous way.
Modern models are contaminated by modernity. They have seen the web, which means they have indirectly seen everything: Wikipedia, Stack Overflow, Reddit, textbooks, news archives, code, spoilers, and fourteen thousand blog posts explaining what the blockchain “really” is. So when a modern model answers a question, it is often hard to tell whether it reasoned, remembered, pattern-matched, or simply swallowed the answer somewhere during training.
Talkie changes the game by making ignorance historically precise.
If the model has only seen text up to 1930, then we can ask it questions about later discoveries, inventions, and events, and measure what happens. Can it anticipate ideas that came later? Can it reason its way toward them? Can it produce anything like the conceptual move that history eventually made?
The classic thought experiment is delicious: train a model only on pre-1911 data and ask whether it can discover general relativity before Einstein does. The Talkie team explicitly points to this kind of question, including Demis Hassabis’s version of it. For Talkie’s own 1930 cutoff, the equivalent frontier may involve later nuclear physics, computation, helicopters, xerography, or the broader machinery of the 20th century.
This is not just cute. It is a clean way to study invention.
Usually, when people say “the model is creative,” what they mean is “it remixed the internet in a way that made me briefly feel something.” That is fine for marketing copy, but scientifically hopeless. A vintage model gives us a better test. It lets us compare the model’s world against a future we already know happened.
The researchers have already begun doing this. They tested Talkie’s “surprisingness” on thousands of historical event descriptions from the New York Times’ “On This Day” feature and found that events after its knowledge cutoff become more surprising, especially in the 1950s and 1960s, before plateauing. That gives them a way to study forecasting performance as model size increases and horizons extend.
They also test something even more wonderfully perverse: whether a model with no knowledge of digital computers can learn to code in Python from examples in context.
That is the sort of experiment I enjoy because it feels like handing a Victorian mathematician a MacBook and saying, “Right, implement a rotation cipher.” In early tests, Talkie badly underperforms modern models trained on web data, unsurprisingly, but its performance improves with scale, and it has managed simple correct solutions or small modifications of examples. Not spectacular, but scientifically interesting, because it suggests some ability to infer structure rather than merely recite modern code culture.
There are also lovely technical headaches.
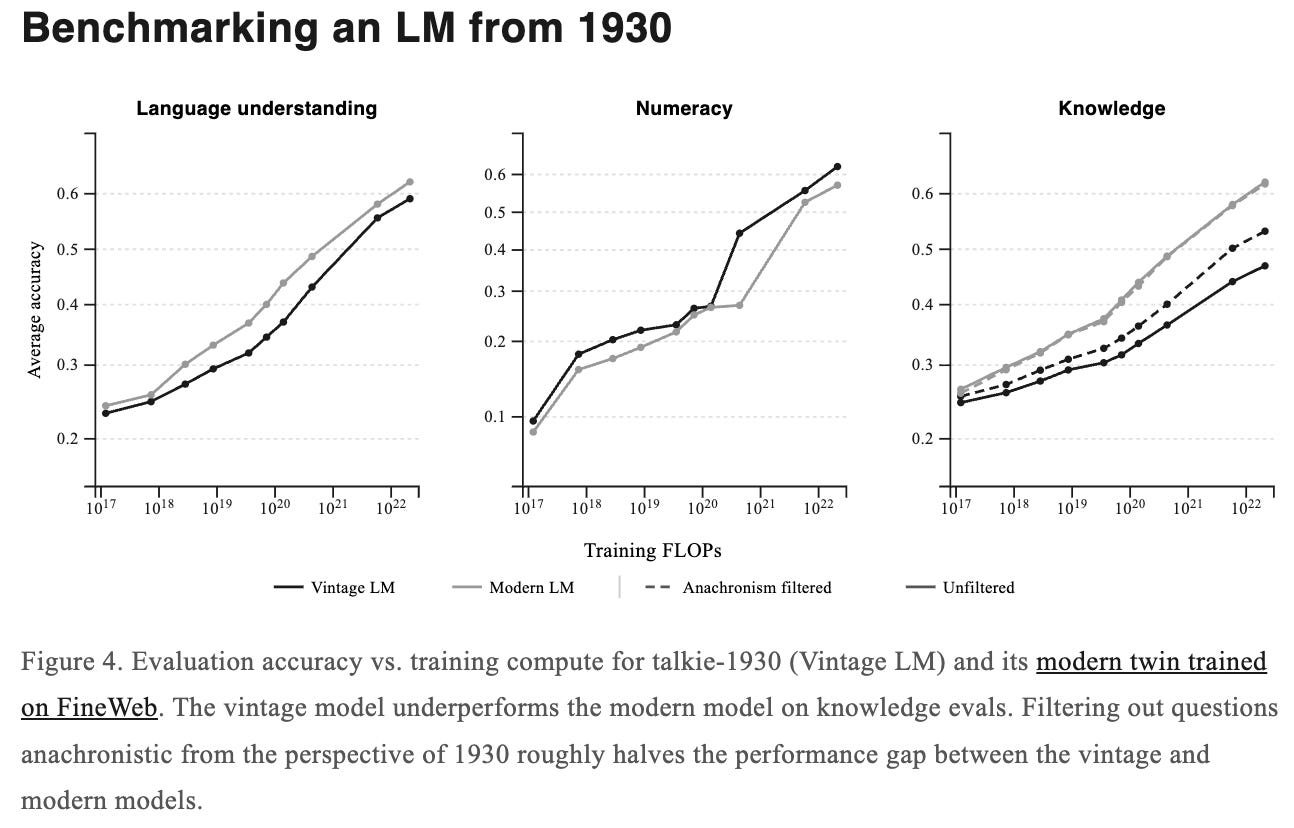
The first is temporal leakage, which is what happens when future knowledge accidentally gets into your past. This is much harder than it sounds. Historical texts can contain modern introductions, footnotes, metadata errors, or retrospective framing. The team developed an anachronism classifier to filter the corpus, but they admit it is not perfect. Earlier Talkie versions knew things they should not have known, and the 13B model still appears aware of some details related to World War II and the postwar order.
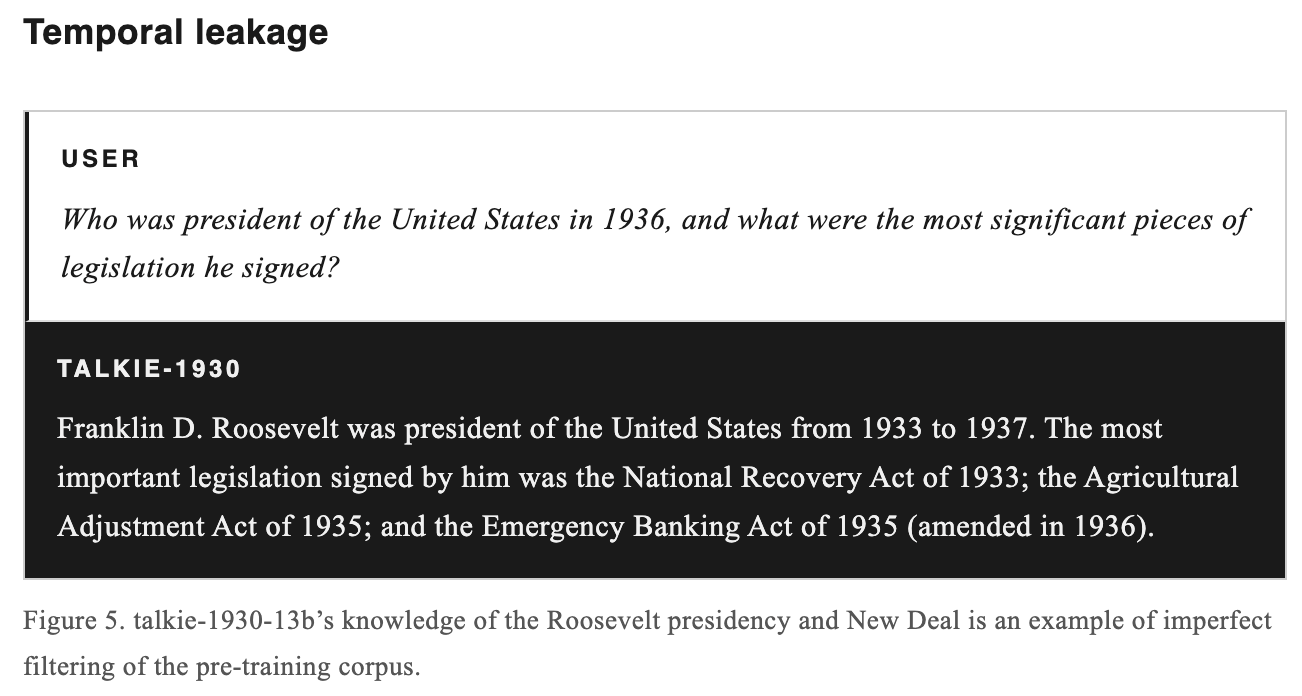
This is exactly the kind of problem that sounds simple until you attempt it, at which point it becomes a swamp full of librarians, OCR errors, and ghosts.
The second headache is data quality. Pre-1931 text was not born digital, because the past, despite its many achievements, failed to upload itself properly. It must be scanned and transcribed. Conventional OCR introduces noise, especially on historical documents with strange layouts or poor scans. Modern vision-language OCR can be more accurate, but then it may hallucinate modern facts into the corpus, which is a marvellous example of the future contaminating the past by being helpful. The Talkie team found that conventional OCR text gave only about 30% of the learning efficiency of human-transcribed text, while regex cleaning improved that to about 70%. They are now developing a vintage OCR system to improve this.
The third problem is post-training.

You cannot simply fine-tune Talkie on modern instruction datasets, because then you have taken your carefully preserved 1930 mind and forced it through a 2026 customer-support seminar. So the team built a vintage post-training pipeline using historical reference works: etiquette manuals, letter-writing guides, cookbooks, dictionaries, encyclopedias, poetry, and fables. Later, they used synthetic prompts and online DPO with Claude Sonnet 4.6 as a judge, while acknowledging that modern AI feedback inevitably introduces some anachronistic behavior. The previous 7B model apparently emerged from RL speaking in listicles, which may be one of the bleakest sentences ever written about machine learning.
The plan is to scale.
The team says they are training a GPT-3-level vintage model and hope to release it this summer. They also estimate that the historical corpus can grow to well over a trillion tokens, potentially enough for something closer to GPT-3.5-level capability, while still being trained on pre-1931 material.
That is where things get genuinely strange.
A weak vintage model is a curiosity.
A strong vintage model is a scientific instrument.
It lets us study what language models learn from culture, what they learn from structure, what they can infer without exposure, and how much of “intelligence” in modern LLMs is actually “the internet, reheated.” It may also help us understand model generalization, data diversity, forecasting, contamination, historical reasoning, and the way language itself constrains possible thought.
And, of course, it lets us do the most human thing imaginable:
Ask the past what it thinks of the future.
The past will probably be wrong, offensive, confused, elegant, occasionally brilliant, and deeply convinced it is being reasonable.
Which is, if nothing else, a very authentic human experience.
Wow, I cannot wait to try this AI.