The Missing Layer in AI Tooling Is Not Another Agent. It Is Identity.
AI does not just need better models. It needs a portable, explicit way to understand the human on the other side of the interface.

The Missing Layer in AI Tooling Is Not Another Agent. It Is Identity.
There is a particular kind of modern absurdity that appears the moment you start using more than one AI tool seriously.
One model knows how you write. Another knows how you code. A third one remembers, vaguely, that you dislike fluffy prose, hype words, and being treated like a Labrador in a productivity webinar. A fourth remembers absolutely nothing and greets you like a stranger in a corridor.
So you do what people do now. You begin copying yourself into machines.
You paste the same preferences, constraints, context, boundaries, tone, and working assumptions into one tool after another, like a Victorian clerk manually updating the census. And somewhere along the way, the whole thing becomes faintly ridiculous. We are supposedly building “intelligent systems,” yet much of the practical work still involves re-explaining who you are every time you open a new window.
That is the problem I wanted to attack with ID.

Not memory in the grand philosophical sense. Not digital immortality. Not another sentimental fantasy about “your AI that truly understands you.”
Something much more useful.
A portable standard for structured human–AI interaction context, which the repository describes as a protocol and reference repo for portable human-AI interaction context, with depth levels, explicit responsibility for freshness, and hook boundaries that orchestration can call instead of relying on hidden chat state.
That last part matters more than it first appears.
Because the modern AI stack has a bad habit of hiding critical things inside product-specific memory, opaque prompts, or chat histories that feel stable until the moment they are not. One day the tool “knows” you. The next day it has forgotten the important part and become strangely enthusiastic about rewriting your work in the tone of a sales intern who has just discovered caffeine.
ID starts from a very different assumption: if context matters, it should be explicit, versioned, portable, and inspectable.
That is the whole idea.
Not “trust the magic.”
Not “the model will learn you.”
Not “surely the platform memory will sort itself out.”
No. Put the human context into a defined layer, make it movable between tools, and stop pretending hidden state is an acceptable foundation for serious work.
The repo frames this in practical terms. The goal is faster onboarding for new tools or agents, less repeated prompt boilerplate, explicit privacy and freshness boundaries, and measurable with-vs-without-ID comparisons instead of ideology-only claims.
Which is refreshingly unromantic.
And that is exactly why I like it.
Because too much of AI tooling is still built around projection. People project memory where there is only retrieval. They project loyalty where there is only local state. They project human continuity onto systems that are, in truth, much more brittle and compartmentalized than the demos imply.
ID is an attempt to stop doing that.
Its structure is intentionally layered. The README describes a smallest-entry path called ID Lite, which gives you a starter profile, handshake, privacy policy starter, and compact portable artifact. Then there is ID Share, intended for safer movement of context between tools or people, with validated artifacts such as interop, compact, and MCP-style surfaces.
That design choice is important because the right answer here is not one giant sacred file full of biography and preferences. It is a protocol surface with clear depth levels and an understanding that context has cost, freshness requirements, and privacy implications.
In other words, ID is not trying to create a soul.
It is trying to create a disciplined human context layer.
Which, in practice, is much more valuable.
The repo also makes another point I think the ecosystem needs badly: orchestration should call explicit hook boundaries rather than rely on hidden chat state. That is a very elegant sentence for a very unglamorous truth. Most AI workflows break not because the model is stupid, but because the context boundary is fuzzy, stale, or trapped in the wrong place.
Once you take that seriously, an entire class of tool design starts to look undercooked.
Because the real problem is not just “how do I prompt better?” It is “how do I maintain a stable, inspectable handoff of human preferences, constraints, privacy rules, and working assumptions across multiple tools and workflows?”
That is the layer ID is trying to occupy.
And in my view, it is a very real missing layer.
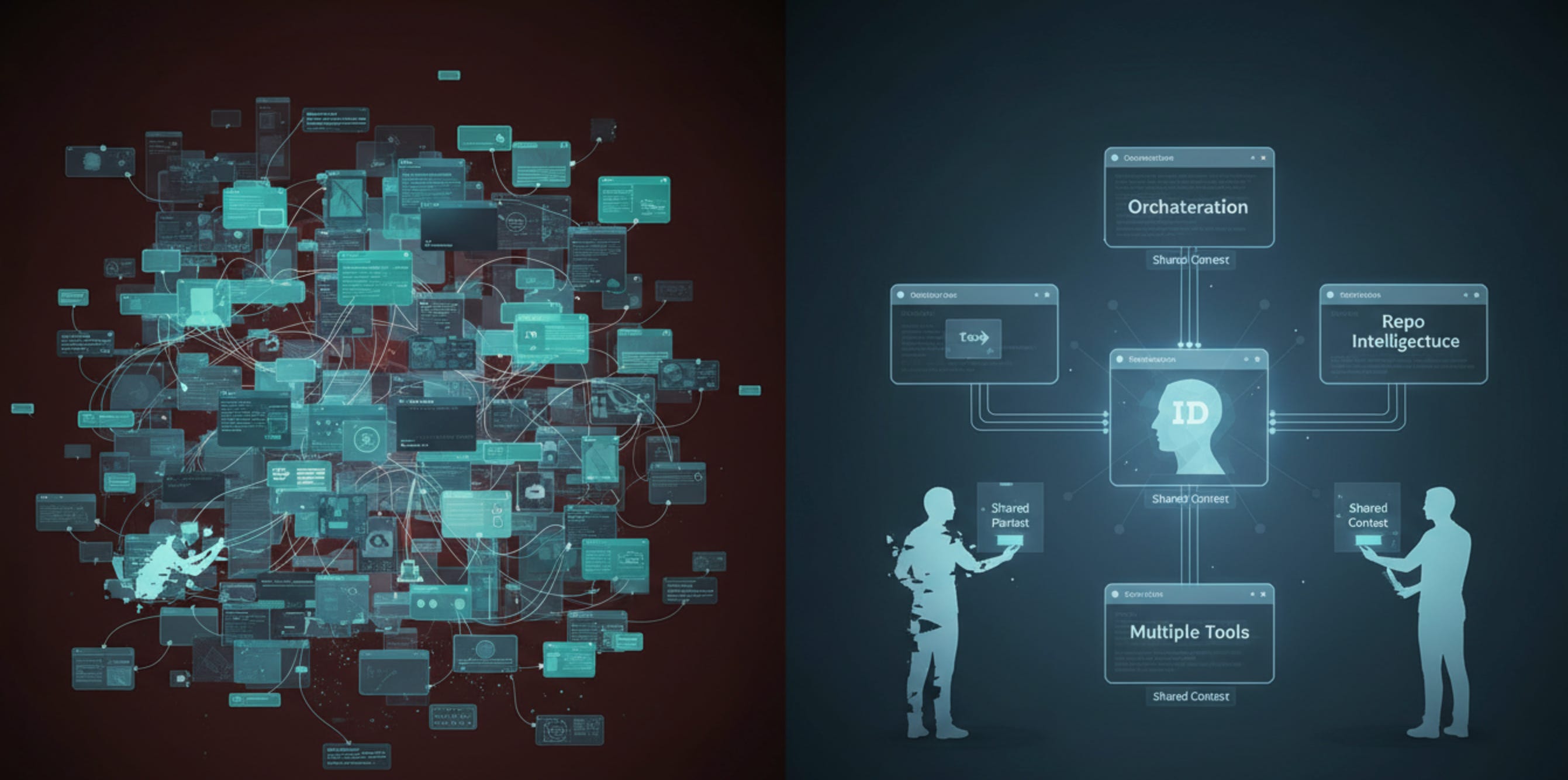
The practical role of ID becomes even clearer when you see it inside the wider stack around it. The repository states that it now functions as the repo-local hook layer for SET-compatible orchestration flows, while remaining the context/protocol layer rather than the orchestration layer itself.
That distinction is not just tidy architecture. It prevents the usual mess where every tool tries to become all tools at once.
In this ecosystem, SET is defined as the thin orchestration layer and GitHub Action entrypoint, while ID is the portable human-AI profile protocol plus repo-local integration hooks for cross-tool context transfer.
That division of labor is, frankly, how more tool ecosystems should be built.
One thing coordinates.
One thing describes the human.
One thing understands the repo.
And the boundaries are explicit.
That repo-intelligence runtime piece is handled by AGENTS.md Generator, or agentsgen, which is described as safe repo docs plus PR Guard plus AI docs bundle for coding agents. Its README explicitly says: “ID reads the human. agentsgen reads the repo. id-context.json connects them.”
That, to me, is one of the cleanest summaries of the whole architecture.
Humans and repositories are not the same thing.
Their context should not be collapsed into one blob.
And a serious stack should know the difference.
This is also why ID now shows up in ABVX Lab, which presents itself as a global catalog for a small but serious stack around SET, agentsgen, ID, repomap, proof loops, and repo-doc workflows. In that catalog, ID is listed as the portable human-AI profile protocol plus repo-local hooks for SET-compatible flows.
So if you want the short version of what ID is for, it is this:
AI tools have become good enough that the bottleneck is no longer only the model.
It is also the human context surface around the model.
Who you are.
How you work.
What you do not want.
What the privacy boundaries are.
What must stay fresh.
What must move with you.
And if that layer remains ad hoc, hidden, manually recopied, or trapped inside one product’s memory, then the whole workflow remains more fragile than it looks.
That is why I built ID.
Not as another AI agent.
Not as a personality simulator.
Not as a messianic “digital you.”
But as a portable standard for the most neglected thing in the stack: the human side of the interface.
And yes, it does not live alone. It is orchestrated together with other tools through SET, appears in the public tool catalog at lab.abvx.xyz / lab.abvx, and sits alongside the repo-doc/runtime layer in AGENTS.md Generator / agentsmd.abvx.xyz.
Which is probably how this should work anyway.
One tool should not pretend to be the whole future.
It should do one layer properly, expose the boundary clearly, and fit into a system that is honest about what each part is for.
That is less theatrical than most AI launches.
But much more useful.